「なんでファイルが思った順番に並ばないの!?」
ファイルやフォルダを名前で並べ替えたとき、漢数字の「一、二、三」や、「上期、下期」が期待通りにソートされなくて困った経験はありませんか?
実はこれ、コンピュータが文字を認識する「文字コード」というルールが原因なんです。
この記事では、なぜそのような現象が起こるのか、その原因となるコンピュータの文字のルール(文字コード)から優しく解説します。
記事を読めば、ソート順の謎が解けるだけでなく、誰でもできる簡単な解決策も分かります。
まずは結論から
ファイル名やフォルダ名が思った通りに並ばないのは、コンピュータがファイル名を「文字コード」という番号順に並べているからです。
漢数字の「一、二、三」や「上、下」という漢字は、数字の大小や順序ではなく、文字コードに割り当てられた番号の順でソートされてしまいます。
多くの場合は、次の手順で解決できます。
- ファイル名の先頭に「01, 02, 03」のような半角数字を追加する
- 「上期・下期」を「1期・2期」や「前期・後期」のような表現に変える
詳しい原因と、その他の解決策はこのあと順番に解説します。
なぜ?漢数字が数字の順番に並ばない理由
多くの人が「一、二、三」と並んでほしいと期待する場面で、コンピュータは「一、三、二」のように、全く違う順番で表示することがあります。
これは、コンピュータが文字を「数字の大きさ」ではなく、「文字コード」という内部的な整理番号で判断しているためです。
特に、現在主流の文字コード体系である Unicode を、広く使われている UTF-8 という形式で扱う場合、漢字は部首と画数の順で整理されています。
| 漢数字 | Unicode(★並び順) | 部首 | 部首の画数 |
|---|---|---|---|
| 一 | U+4E00 | 一部 | 1画 |
| 七 | U+4E03 | 一部 | 1画 |
| 三 | U+4E09 | 一部 | 1画 |
| 九 | U+4E5D | 乙部 | 1画 |
| 二 | U+4E8C | 二部 | 2画 |
| 五 | U+4E94 | 二部 | 2画 |
| 八 | U+516B | 八部 | 2画 |
| 六 | U+516D | 八部 | 2画 |
| 四 | U+56DB | 口部 | 3画 |
上の表を見ると、「一、七、三」は同じ「一部」に属しているため、コード番号が近くなっています。
そして、部首の画数が少ない漢字から順にコードが割り当てられているのが分かります。
このように、漢数字の見た目の「数字としての意味」は、コンピュータの並び順には全く考慮されていないのです。
例えるなら、図書館で本を「本の大きさ」や「色」で並べるのではなく、「整理番号」で並べているのと同じです。
人間にとっては直感的でなくても、コンピュータにとってはそれが最も効率的なルールなのです。
「下期」が「上期」より先に来る!?もう一つのソートの罠
漢数字だけでなく、「2026年上期」「2026年下期」といったフォルダを作った際に、「下期」が「上期」より前に表示されてしまう現象も、文字コードが原因です。
「上」のUnicodeは U+4E0A、「下」は U+4E0B であり、コードポイント(文字コードの番号)自体は「上」の方が小さいです。
| 漢字 | Unicode | 10進数 |
|---|---|---|
| 上 | U+4E0A | 19978 |
| 下 | U+4E0B | 19979 |
それなのに、なぜ順番が逆になってしまうのでしょうか?
これは、一部のシステム(特に日本語環境)では、単純なコードポイント順ではなく、漢字の「音読み」を基準にソートする場合があるためです。
- 上:ジョウ
- 下:カ、ゲ
ひらがなの五十音順で考えると、「か」や「け」は「し」よりも前に来ます。そのため、「下期(かき)」が「上期(じょうき)」よりも先に表示されてしまうのです。
これは、人間が辞書を引くときの感覚に近いルールですが、単純に「上・下」の順で並んでほしい場合には、かえって分かりにくくなってしまいますね。
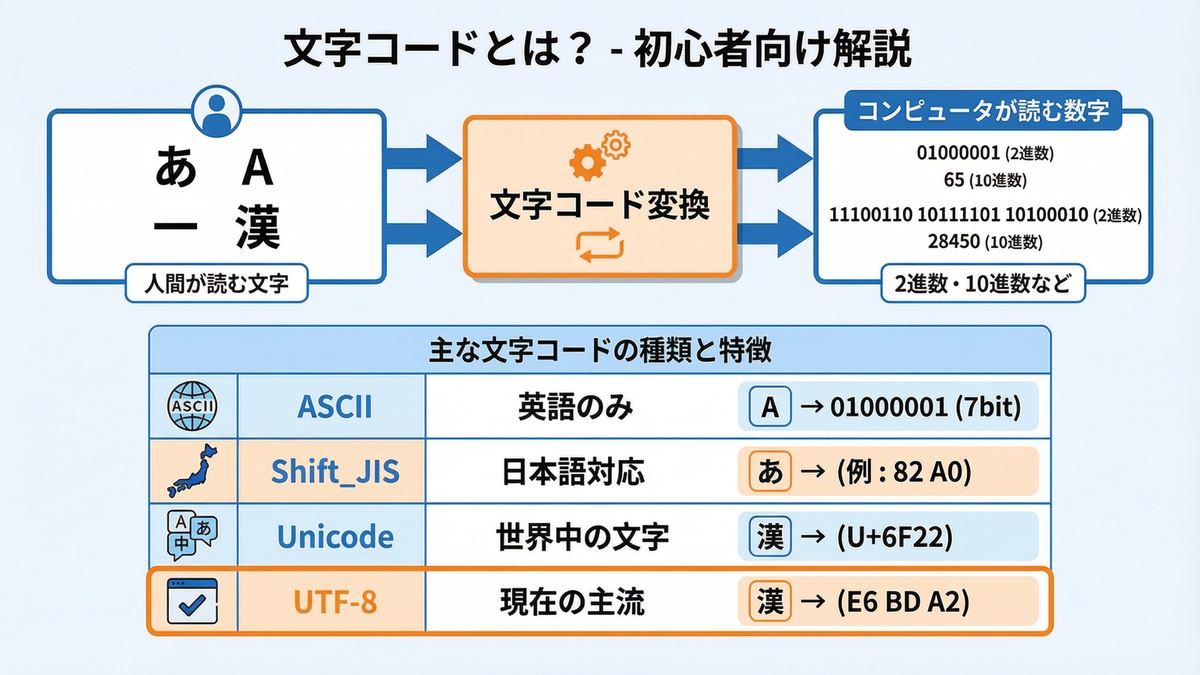
すべての基本「文字コード」とは?
ここまで何度も出てきた「文字コード」という言葉ですが、一体何なのでしょうか。
簡単に言うと、コンピュータが文字を扱うために、一つ一つの文字に割り当てたユニークな番号のことです。
コンピュータは、私たちが使っている「あ」や「A」といった文字そのものを直接理解できません。理解できるのは「0」と「1」の組み合わせである数字だけです。そこで、「A」には「65」、「あ」には「12354」というように、すべての文字に番号を割り振っておき、その番号を使って情報を処理しています。この番号の体系が文字コードです。
文字コードとは、大まかにいえば、文字をコンピュータで処理したり通信したりするために、文字の種類に番号を割り振ったものです。
代表的な文字コードには、以下のようなものがあります。
| 文字コード | 特徴 |
|---|---|
| ASCII | アルファベット、数字、記号など、英語圏で使われる基本的な128文字を収録した、最も基本的な文字コード。 |
| Shift_JIS | ASCIIに加えて、日本語(ひらがな、カタカナ、漢字)を使えるようにした、かつて主流だった文字コード。 |
| Unicode | 世界中のあらゆる言語の文字を一つの体系で扱えるようにした、現在最も広く使われている国際標準の文字コード。 |
| UTF-8 | Unicodeで定義された番号を、実際にデータとして保存・通信する際の形式(符号化方式)の一つ。可変長で効率が良い。 |
今回のソート問題は、このUnicodeのルールによって引き起こされているのです。

【解決策】思い通りに並べるための3つのテクニック
原因が分かったところで、具体的な解決策を見ていきましょう。誰でも簡単に試せる3つの方法を紹介します。
1. ファイル名の先頭に半角数字を付ける
最も確実で簡単な方法が、ファイル名の先頭に 「01」「02」「03」 のように、桁数を揃えた半角数字を追加することです。
01_第一営業部02_第二営業部03_第三営業部
このようにすれば、コンピュータは先頭の数字を優先して並べ替えてくれるため、漢数字や「上期/下期」のソート順に悩まされることがなくなります。
ポイントは、1桁の数字でも「1, 2, 3」ではなく「01, 02, 03」のように桁数を揃えることです。こうすることで、「10」が「2」より前に来てしまうといった事故を防げます。

2. 「上期/下期」の表現を変える
「上期/下期」のソート順問題は、表現を少し変えるだけで解決できます。
2026年_1期,2026年_2期2026年_前期,2026年_後期2026_FH,2026_SH(First Half / Second Half)
このように、音読み順の影響を受けない言葉や、数字・アルファベットに置き換えることで、期待通りの順番に並べることができます。
3. Excelなら「ふりがな」や「ユーザー設定リスト」を活用
Excelでデータを並べ替える場合は、もう少し高度な解決策があります。
- ふりがな情報を修正する: Excelはセルの「ふりがな」情報を元にソートを行います。漢数字のセルに、数字としての読み(いち、に、さん)を正しく設定することで、意図した順番に並べ替えられます。
- ユーザー設定リストを使う: 「上期、下期」や「社長、部長、課長」など、独自の並び順をあらかじめExcelに登録しておく機能です。一度登録すれば、いつでもその順番でソートできるようになります。
それでもダメな場合の応用テクニック
上記の基本的な方法で解決しない、もっと複雑なケースでは、少し専門的な知識が必要になる場合があります。
例えば、プログラミングで漢数字を含む文字列を扱う場合、単純なソート機能を使うのではなく、漢数字を一度アラビア数字(1, 2, 3)に変換してから並べ替える、といった処理を組み込む必要があります。
また、データベースでは、並べ替えのルール(照合順序)を細かく設定できる場合があります。文字コードのルールではなく、言語のルールに基づいたソートを選択することで、より自然な順序で並べ替えることが可能です。
まとめ
今回は、漢数字や「上期/下期」が思った通りに並ばない原因と、その解決策について解説しました。
- コンピュータは、文字を文字コードという番号順でソートする。
- 漢数字は、数字の大小ではなく、部首や画数順にコードが割り当てられているため、バラバラに並ぶ。
- 「上期/下期」は、日本語環境だと音読み順でソートされることがあるため、「下期」が先に来ることがある。
- 解決策として、ファイル名の先頭に「01, 02」のような連番を付けるのが最も簡単で確実。
この仕組みを理解しておけば、ファイル管理やデータ整理が格段にスムーズになります。もし周りに同じことで困っている人がいたら、ぜひこの知識を教えてあげてください。